Overview
Event cameras are neuromorphic sensors that output asynchronous per-pixel brightness changes rather than full frames, enabling extremely low latency and high dynamic range perception. This project builds and connects the full stack needed to jointly optimize an event camera’s optics and event generation alongside downstream flow estimation networks. While ultimately unsuccesful, differentiability was proven along each rung of the differentiable ladder. Each section below covers a tool or experiment that moves toward that goal. The final endpoint is optimization for a specific robotics task.
 Figure 1: The end-to-end differentiable pipeline connecting lens geometry, event simulation, and optical flow.
Figure 1: The end-to-end differentiable pipeline connecting lens geometry, event simulation, and optical flow.
Custom Frame-Difference Emulator
As a starting point, I wrote a naive DVS emulator from scratch (event.py). It converts frames to grayscale, computes log-intensity L = log(I + ε), and fires ON/OFF events when the change exceeds a threshold:
ON event: ΔL ≥ threshold
OFF event: ΔL ≤ −threshold
Output is a CSV of (t, x, y, p) tuples plus a visualization video using an exponential-decay event accumulator. It has no sensor physics but it’s fast and fully interpretable as a baseline.
 Figure 2: Event accumulation visualization from the custom frame-difference emulator
Figure 2: Event accumulation visualization from the custom frame-difference emulator
v2e
v2e is a high-fidelity DVS simulator with full sensor physics[1] . Key features:
- Frame interpolation: Upsamples video to high frame rates before event generation
- Photoreceptor model: 1st-order IIR lowpass filter with intensity-dependent bandwidth
- Realistic noise: per-pixel threshold variation (
σ_threshold), leak events, shot noise, and refractory periods - Outputs AEDAT/H5 formats compatible with standard event-camera toolchains
v2e is significantly more realistic than the naive approach, but its simulation graph is not differentiable.
 Figure 3: Output from v2E event emulator.
Figure 3: Output from v2E event emulator.
SENPI (senpi_ebi)
SENPI wraps the same physics as v2e in a PyTorch nn.Module, making the entire simulation differentiable via autograd[2]. EventSimulator.forward(I) returns both a sparse event tensor (t, x, y, p) and dense event accumulation frames (eframes).
2. Differentiable Optics with DeepLens
DeepLens implements differentiable ray tracing and wave optics[3]. GeoLens handles refractive lenses; DiffracLens handles diffractive ones. Lens surface radii and thicknesses are PyTorch parameters, so gradients flow from any downstream loss all the way back to lens geometry.
To verify the gradient chain, I built a minimal E2E demo:
- Scene: synthetic checkerboard translated across frames to produce motion
- Pipeline:
GeoLens.render()→ SENPIEventSimulator→ Sobel edge-energy loss on event frames - Loss: maximize edge sharpness while penalizing trivial high-activity:
loss = −(edge − λ·activity) - Optimizer:
lens.get_optimizer()with per-parameter learning rates for radii and thicknesses
Gradient flow was verified to be non-zero end-to-end through optics → events → loss.
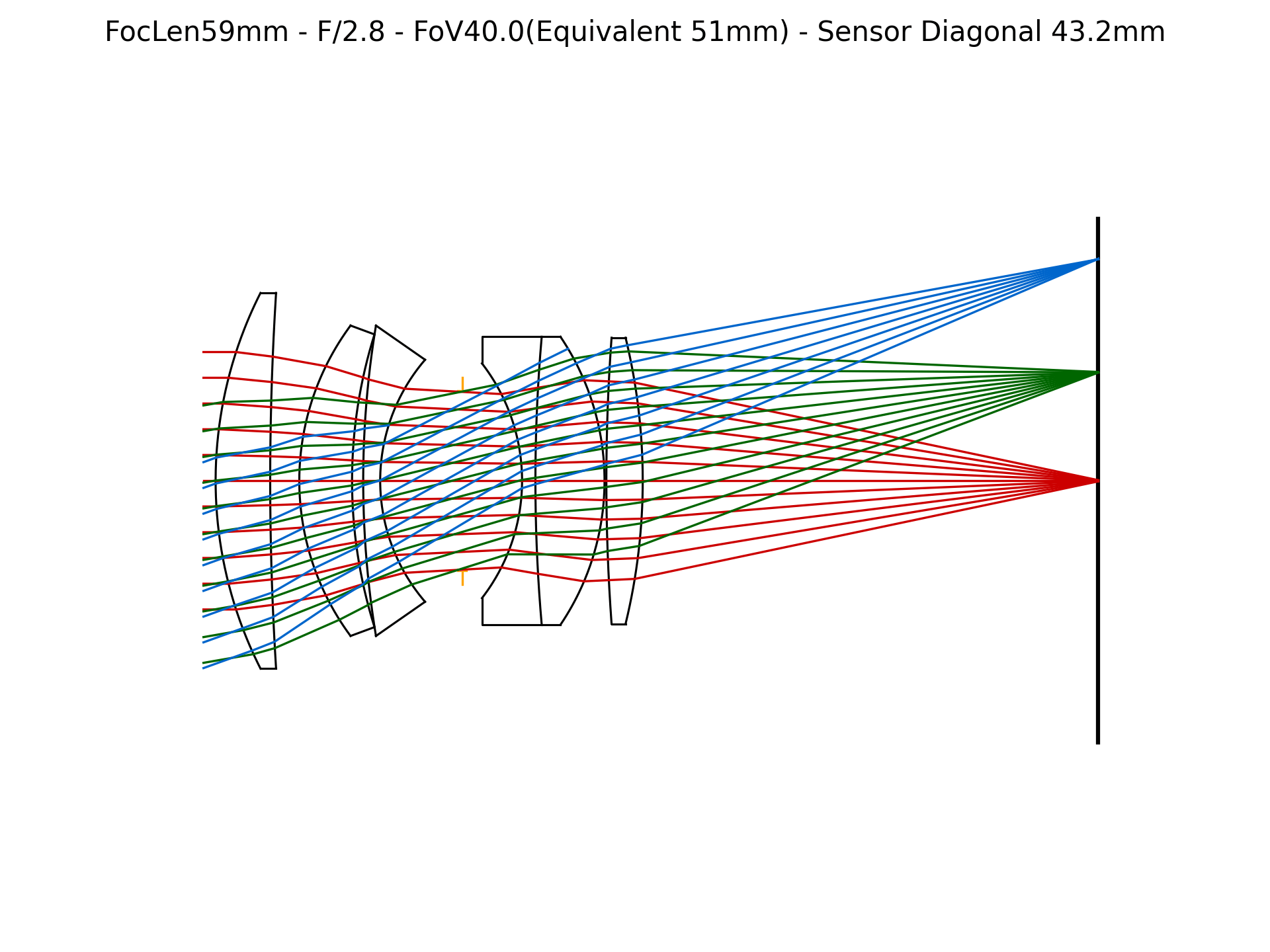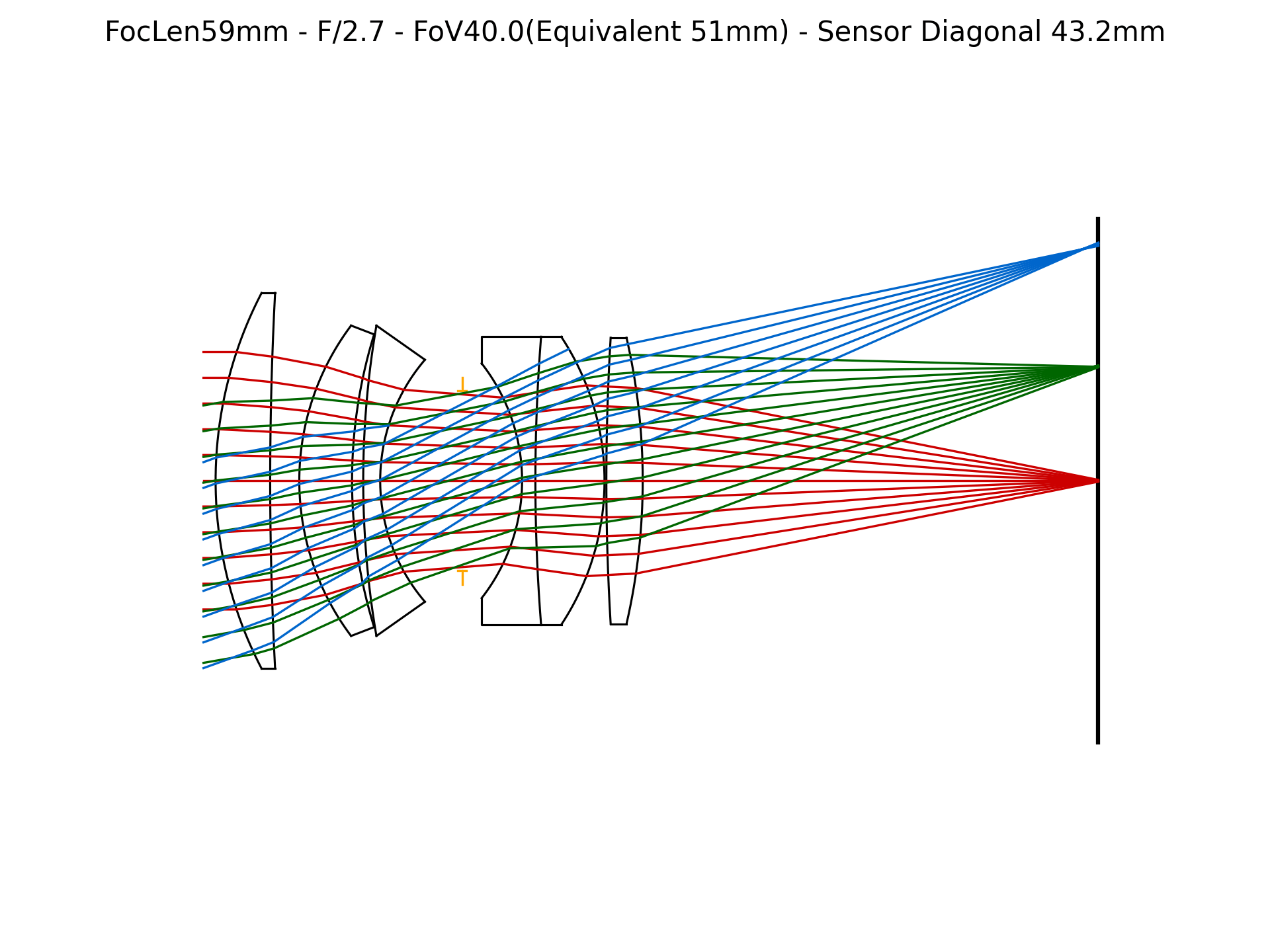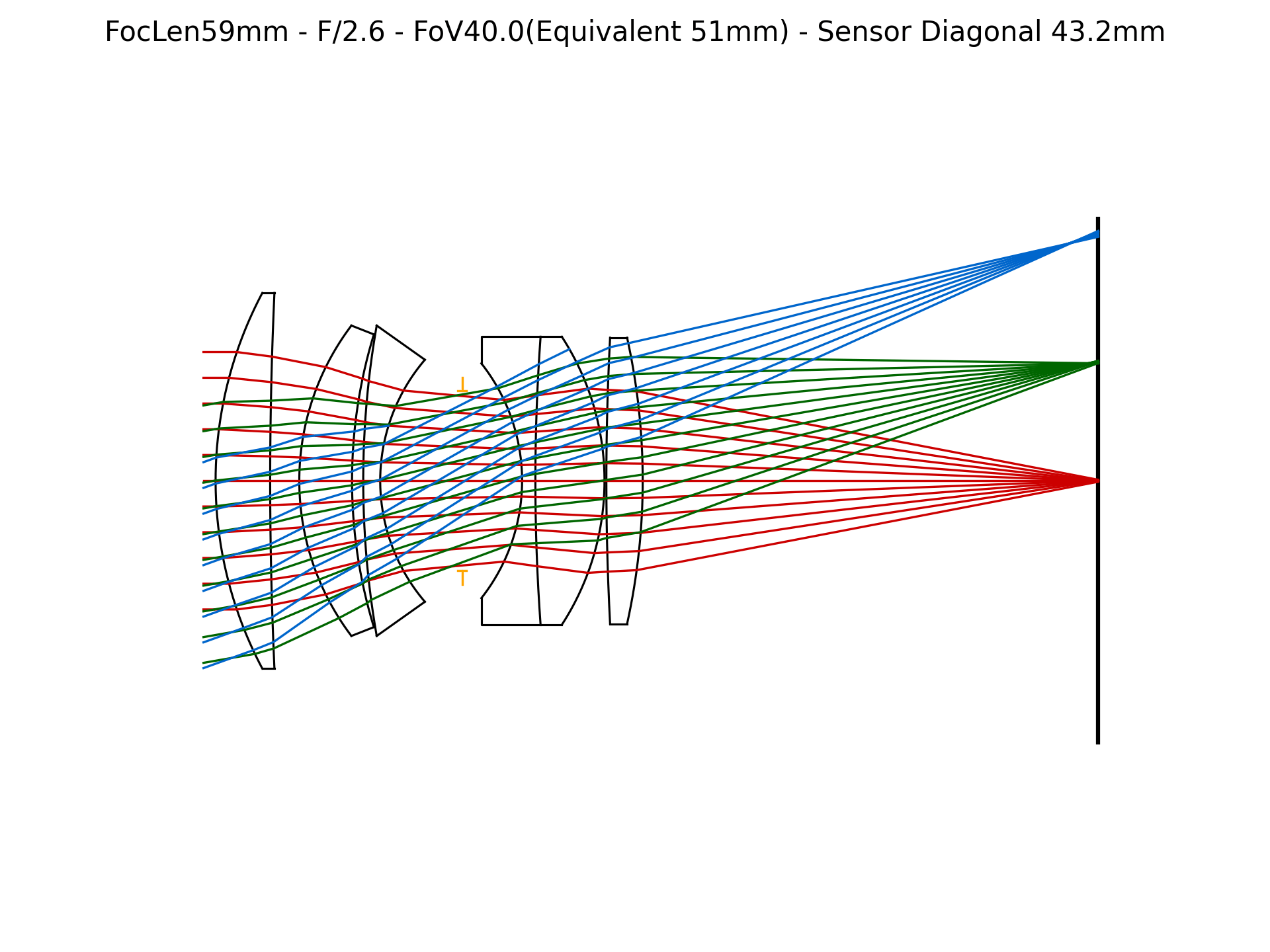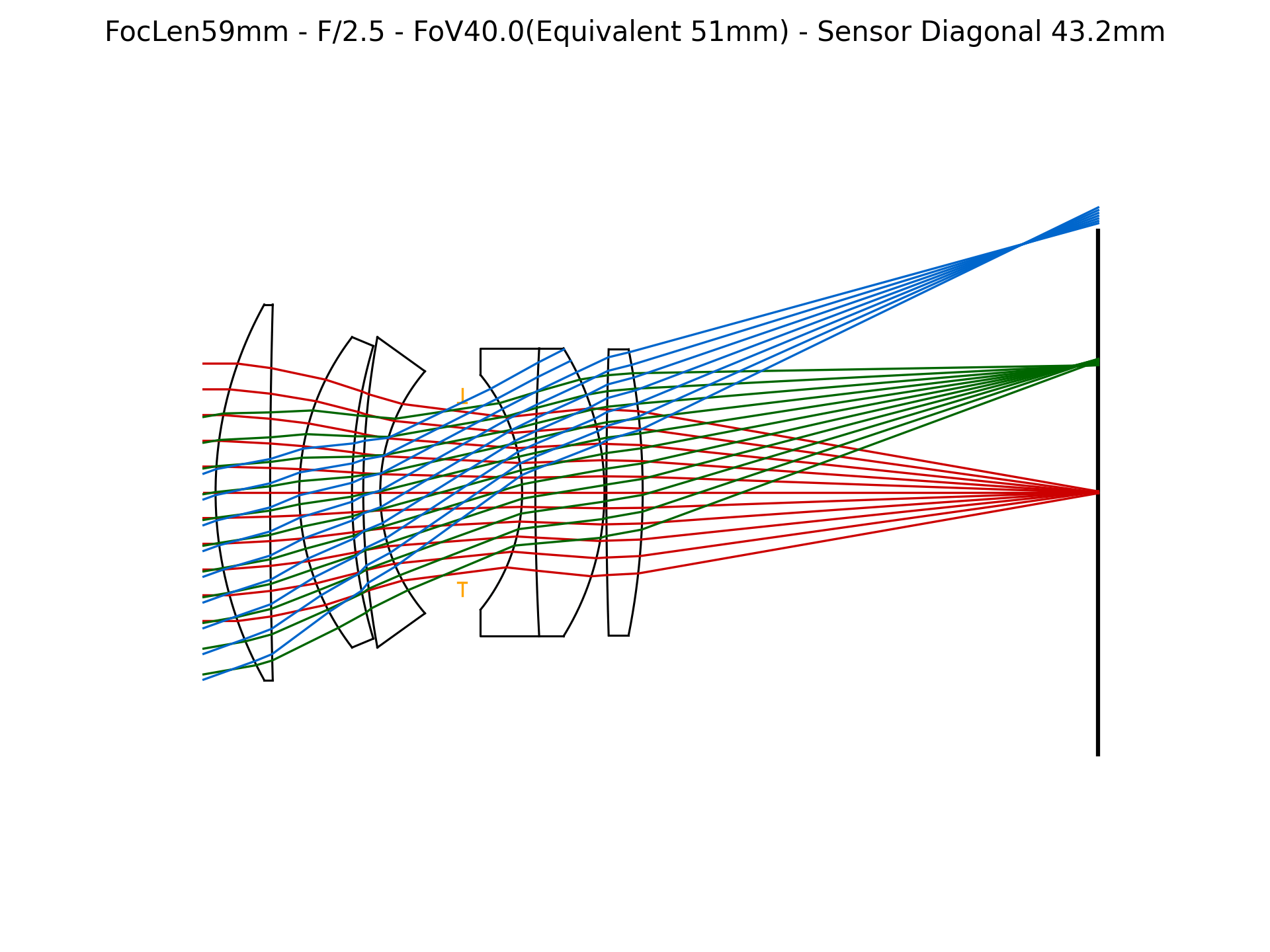 Figure 4: Lens surface parameter evolution during E2E optimization. Parameters converge toward configurations that maximize downstream edge sharpness in event frames.
Figure 4: Lens surface parameter evolution during E2E optimization. Parameters converge toward configurations that maximize downstream edge sharpness in event frames.
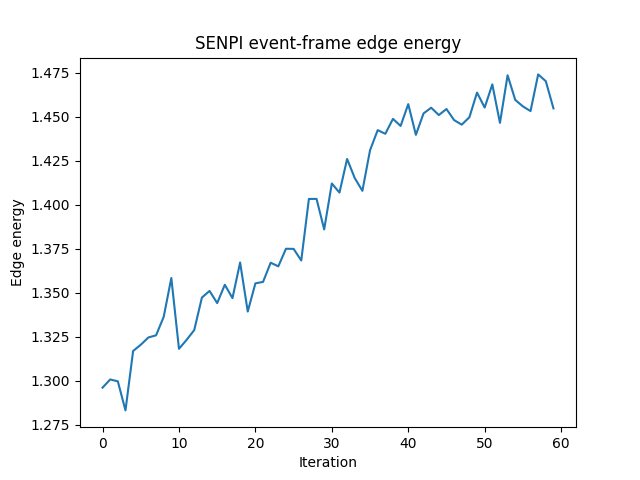 Figure 5: Sobel energy change over time during E2E optimization
Figure 5: Sobel energy change over time during E2E optimization
3. Synthetic Data Generation with IsaacSim
For training the flow network, I generated synthetic event sequences using Nvidia Omniverse/Replicator with ground-truth optical flow and 6-DOF pose.
Dataset: 5 diverse camera trajectories × 600 frames = 3,000 total frames
Trajectory types:
- Orbital paths at variable radii and speeds
- Radial oscillations
- Vertical oscillations
- Segment IDs to filter sequences crossing trajectory boundaries
 Figure 6: Sample IsaacSim frames with the camera output (left) and ground-truth optical flow overlay (right).
Figure 6: Sample IsaacSim frames with the camera output (left) and ground-truth optical flow overlay (right).
4. The Differentiability Problem
Event cameras produce discrete, binary outputs. Gradients cannot flow through a hard threshold. Two approaches solve this.
Approach 1: SENPI Dense Event Frames
SENPI’s eframes aggregate events over time windows via differentiable PyTorch ops.
Approach 2: soft_events() — Sigmoid Sharpening
A custom differentiable approximation replacing hard thresholding with a sigmoid:
def soft_events(I, thr=0.1, sharpness=50.0, eps=1e-6):
L = torch.log(I.clamp_min(eps))
dL = L[1:] - L[:-1] # [F-1, H, W]
Epos = torch.sigmoid(sharpness * (dL - thr)) # smooth ON probability
Eneg = torch.sigmoid(sharpness * (-dL - thr)) # smooth OFF probability
return Epos, Eneg
At sharpness=50, the sigmoid closely approximates a step function while remaining differentiable everywhere. Epos, Eneg ∈ [0, 1] represent soft firing probabilities rather than binary events.
Key finding: The SENPI sparse events tensor does not carry gradients — event positions are discrete indices. Gradients must flow through either the dense eframes or the soft approximation.
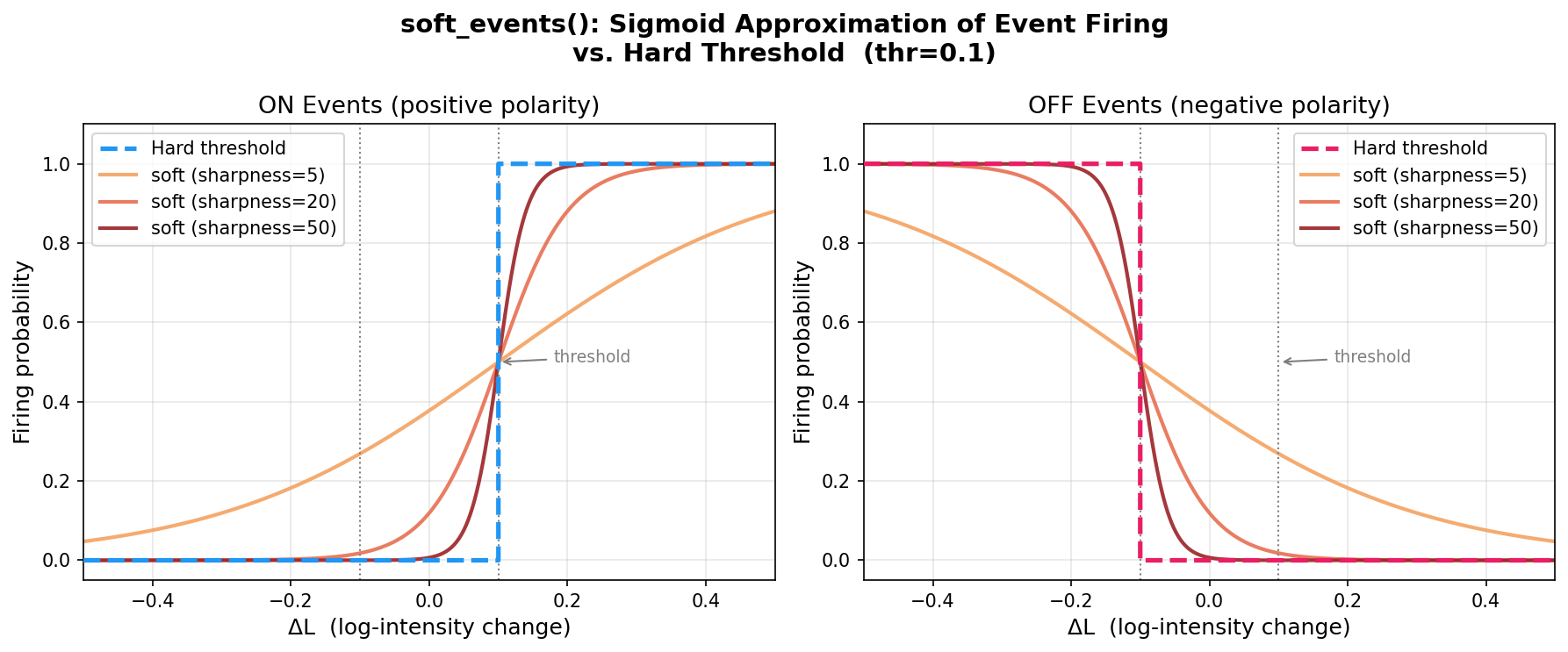 Figure 7: Sigmoid approximation of the event threshold at varying sharpness values. At sharpness=50 the sigmoid closely approximates a hard step while remaining differentiable.
Figure 7: Sigmoid approximation of the event threshold at varying sharpness values. At sharpness=50 the sigmoid closely approximates a hard step while remaining differentiable.
5. Flow Network Integration
Spike-FlowNet
Spike-FlowNet is a hybrid SNN+ANN encoder-decoder for event-based optical flow, pretrained on MVSEC real outdoor sequences[4]. Input format: [B, 4, H, W, T_bins].
Several problems arose integrating it into this pipeline:
- Gradient instability: IF neurons output binary spikes; surrogate gradients are unreliable when fine-tuning outside the original data distribution.
- 5D input format: Required building
soft_events_to_spike_input()to reshape and bin soft events, introducing hard bin-boundary artifacts. - Domain mismatch: Pretrained weights trained on real DVS data did not transfer to synthetic soft events with different statistics.
- Event sparsity: Synthetic scenes produced far fewer events than real outdoor sequences, causing many batches to be skipped (
MIN_EVENT_ACTIVITY = 10.0). - Resolution mismatch: MVSEC resolution required resizing and flow rescaling for 256×256 IsaacSim data.
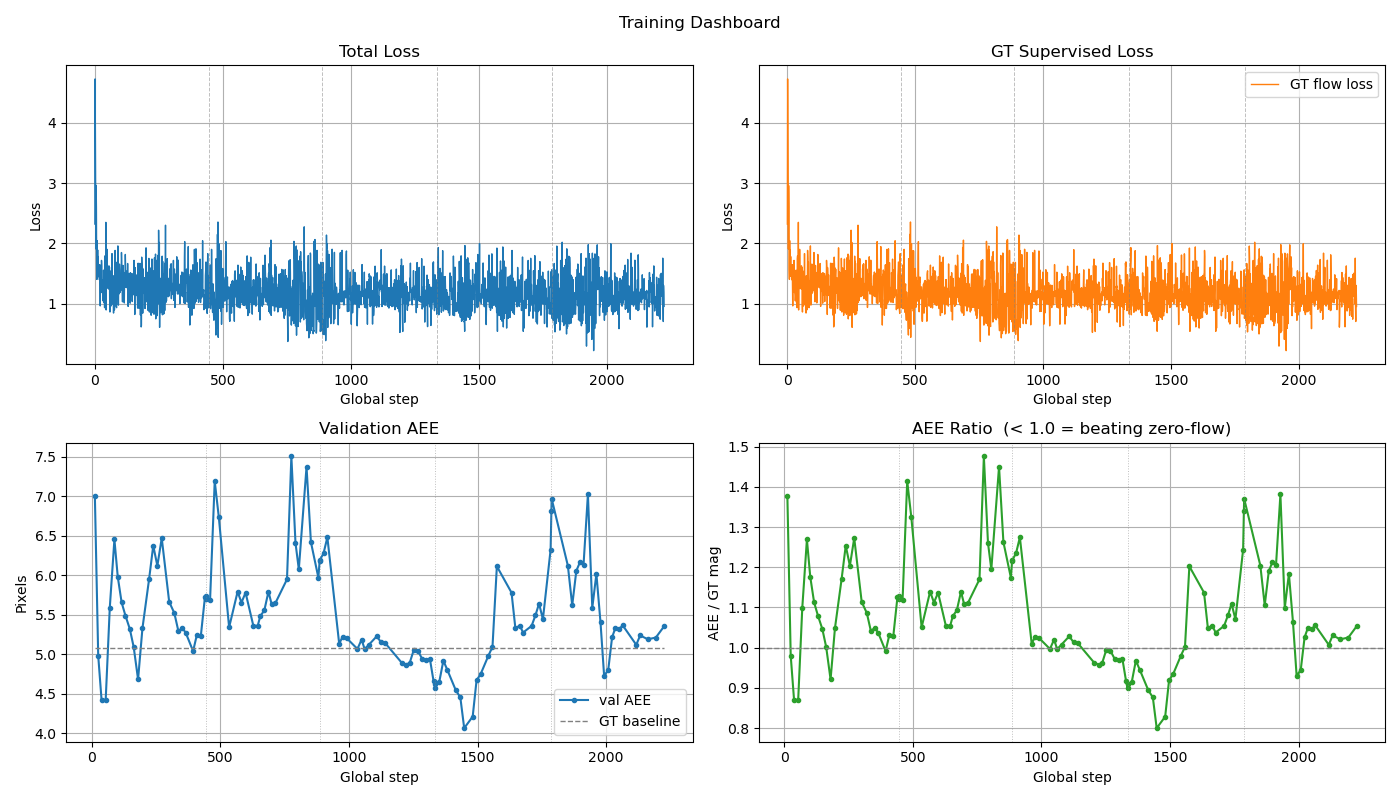 Figure 8: Spike-FlowNet training loss and AEE validation.
Figure 8: Spike-FlowNet training loss and AEE validation.
6. Camera Placement as a Differentiable Design Variable
Camera placement evaluation raises an interesting question: if orientation measurably affects downstream task performance, can it be optimized rather than hand-chosen? Different mounting orientations provide fundamentally different observability over robot velocity axes. Cvent flow encodes motion projected onto the image plane, so a given mounting is informative about some velocity components and structurally blind to others. A forward-facing camera sees ego-motion clearly but loses sensitivity to lateral drift; a downward-facing camera reads ground texture flow well but is insensitive to yaw. No single fixed orientation is optimal across all axes simultaneously.
Adding placement to the optimization means parameterizing the camera’s 6-DOF pose on the robot body as a learnable variable and differentiating the rendering step with respect to that pose.
7. The Full Differentiable Chain
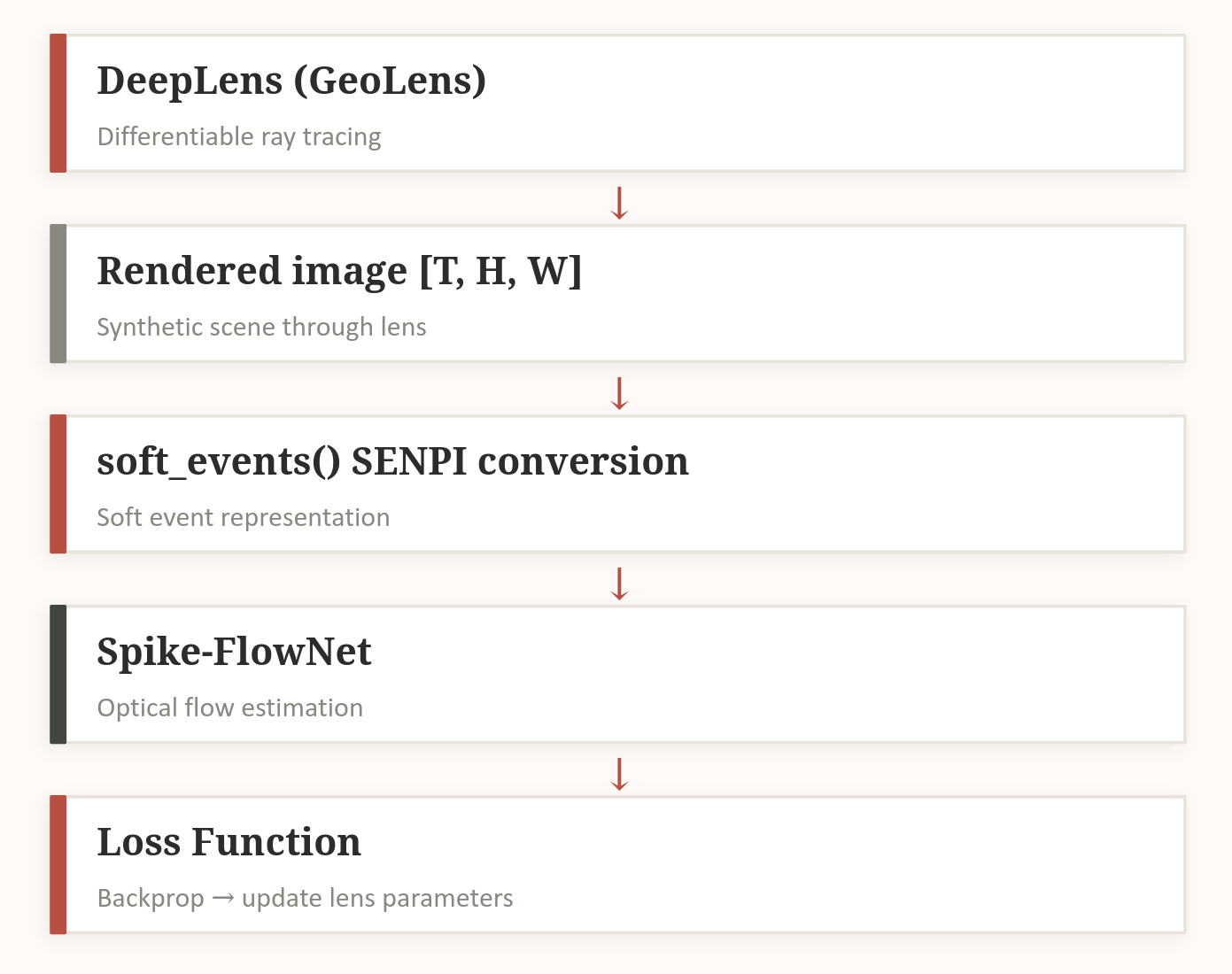 Figure 9: Spike-FlowNet training loss and qualitative comparison of predicted optical flow vs. IsaacSim ground truth.
Figure 9: Spike-FlowNet training loss and qualitative comparison of predicted optical flow vs. IsaacSim ground truth.
Gradient flow was verified at each junction:
- Lens → Image: via DeepLens differentiable ray tracing
- Image → Events: via
soft_events()sigmoid approximation - Events → Flow: via FlowNetEvents convolutional encoder
Open question: Full end-to-end lens co-optimization with event-based flow on realistic robot trajectories — jointly updating lens geometry, camera placement, and network weights for a specific downstream robotic sensing task.
References
[1] Y. Hu, S.-C. Liu, and T. Delbruck, “v2e: From video frames to realistic DVS events,” in Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Jun. 2021, pp. 1312–1321. [Online]. Available: https://arxiv.org/abs/2006.07722
[2] J. L. Greene, A. Kar, I. Galindo, E. Quiles, E. Chen, and M. Anderson, “A PyTorch-enabled tool for synthetic event camera data generation and algorithm development,” Georgia Tech Research Institute, Mar. 2025. [Online]. Available: https://arxiv.org/abs/2503.09754
[3] X. Yang, Q. Fu, and W. Heidrich, “Curriculum learning for ab initio deep learned refractive optics,” Nature Communications, Feb. 2023. [Online]. Available: https://arxiv.org/abs/2302.01089
[4] C. Lee, A. K. Kosta, A. Z. Zhu, K. Chaney, K. Daniilidis, and K. Roy, “Spike-FlowNet: Event-based optical flow estimation with energy-efficient hybrid neural networks,” in Proc. European Conference on Computer Vision (ECCV), Glasgow, UK, Aug. 2020, pp. 366–382.