Overview
Utilizing SAM3 for class Agnostic Segmentation, and a combination of geometric and clip-embedded similarity scores, I have implemented an open-vocabulary 3D memory alongside the Nav2 and RTAB-Maps autonomous navigation stack. Using a simple text query, Unitree Go2 can be directed to navigate to any object it has seen in it’s surroundings with no prior training in that environment.
Demo
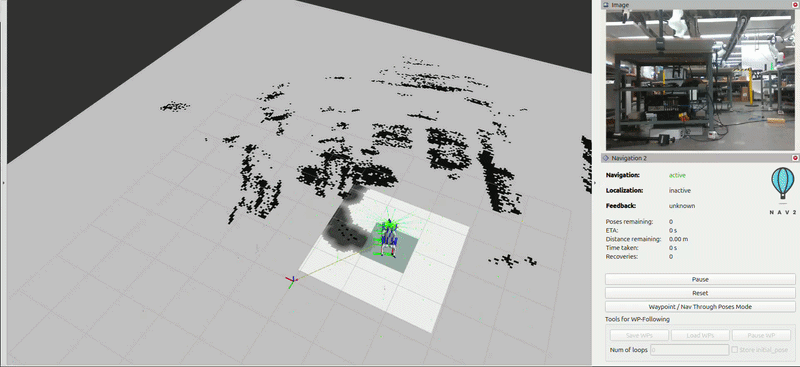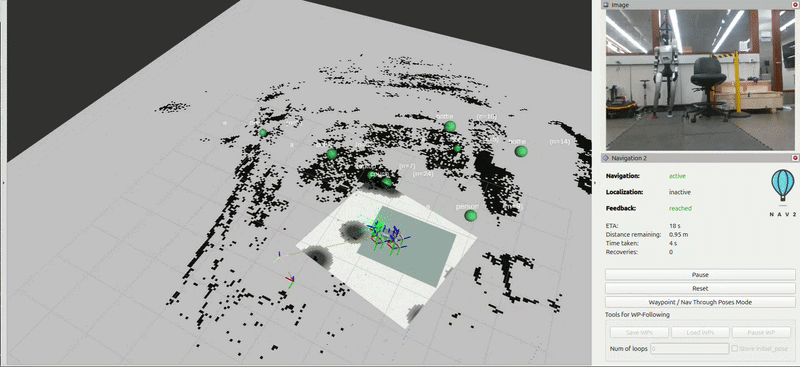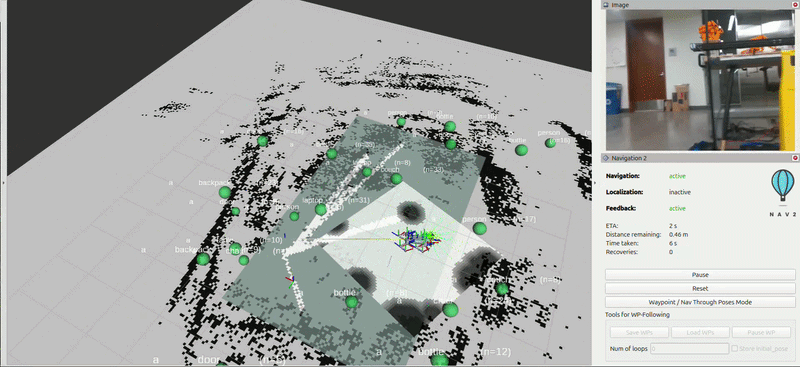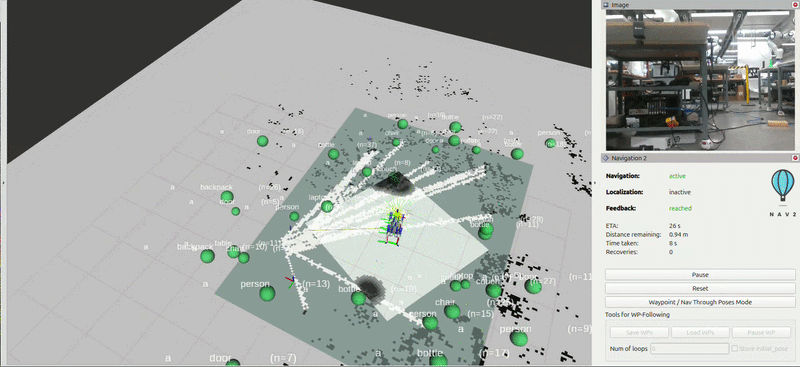
After building out a 3D map and semantic graph of it’s environment, the Go2 autonomously navigates to items based off simple descriptions (i.e. ‘red balloon’, ‘yellow sign’, ‘orange jacket’). After an object is flagged, its marker representation turns red in the concept graph.
Overall System Architecture
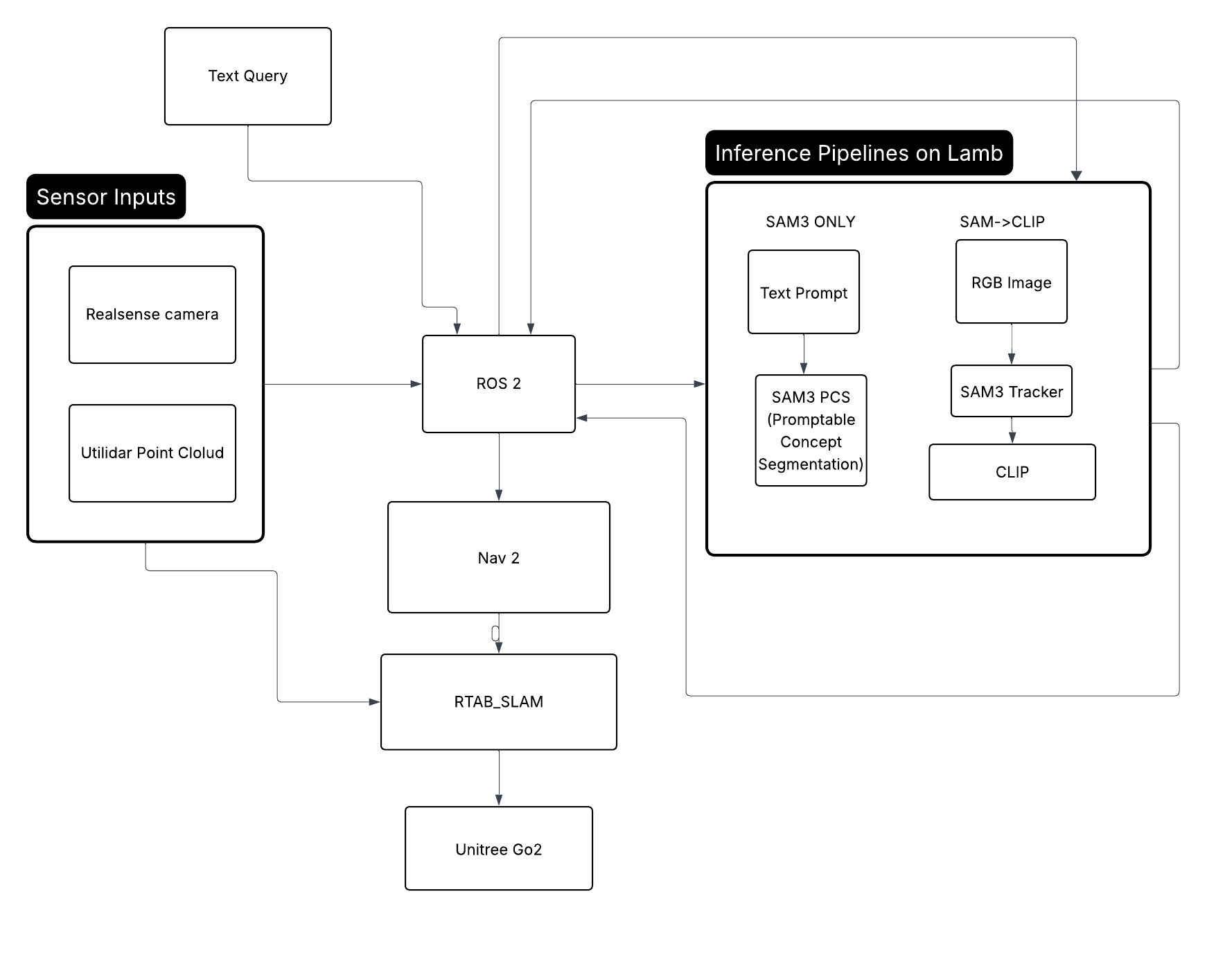
Generating a Graph of Concepts
Inspired by ConceptGraphs (Gu et al., 2023)
1. Segmentation — SAM3 (Segment Anything Model 3)
SAM3 is used to produce object masks from the RGB image. Two modes are used:
Automatic Grid Mode (sam_clip pipeline)
An 8×8 uniform grid of foreground prompt points is generated across the image. SAM3 segments from each prompt point, producing a set of binary masks $\{M_k\}$. Masks smaller than 1500 pixels are discarded as noise.
Text-Prompted Mode (sam3_only pipeline)
SAM3 PCS (Prompt-Conditioned Segmentation) accepts a natural language string directly, returning masks ranked by confidence score. This is limited to finding objects in the robot’s direct field of vision, and does not initiate memory.
2. Visual-Semantic Embeddings — CLIP (ViT-B/32)
CLIP maps both images and text into a shared 512-dimensional embedding space.
Image Embedding
For each mask $M_k$, a crop is extracted and the background is blurred to focus attention:
$$\mathbf{v}_k = \frac{f_I(c_k)}{\|f_I(c_k)\|_2} \in \mathbb{R}^{512}$$where $f_I$ is the CLIP image encoder and $c_k$ is the masked crop.
Text Embedding
For a query string $q$:
$$\mathbf{t} = \frac{f_T(q)}{\|f_T(q)\|_2} \in \mathbb{R}^{512}$$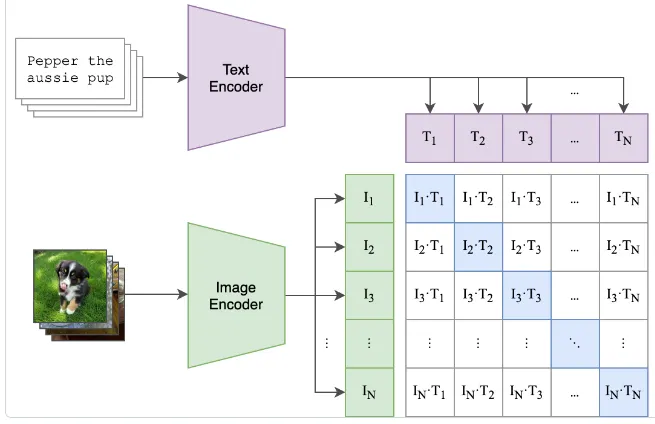 Figure 1: Architecture of CLIP model (taken from the original paper)
Figure 1: Architecture of CLIP model (taken from the original paper)
Cosine Similarity
All comparisons between embeddings use cosine similarity. Since vectors are L2-normalized, this reduces to a dot product.
Background Filtering
A crop is discarded if its CLIP embedding is too similar to any background concept (e.g. “wall”, “floor”, “ceiling”).
Label Classification
The crop is classified by finding the highest-similarity label from a candidate set $\mathcal{L}$.
3. Object Association & Merging
Each new detection must be matched to an existing object or registered as new.
Pre-filter
Candidate objects with Euclidean distance greater than $2 \times d_{\text{thresh}}$ are skipped:
$$\|{\mathbf{p}_{\text{new}} - \mathbf{p}_i}\|_2 > 2 \times 0.75 = 1.5 \text{ m} \quad \Rightarrow \text{skip}$$Candidates with CLIP similarity below threshold are skipped.
Joint Score
Remaining candidates are scored by a joint geometric and semantic metric:
$$s_{\text{geo}} = \max\!\left(0,\; 1 - \frac{\|\mathbf{p}_{\text{new}} - \mathbf{p}_i\|_2}{d_{\text{thresh}}}\right)$$$$s_{\text{joint}} = s_{\text{geo}} \cdot \text{sim}(\mathbf{v}_{\text{new}}, \mathbf{v}_i)$$The candidate with the highest $s_{\text{joint}}$ is selected for merging.
4. Object State Update (Running Average)
When a detection is merged into an existing object with observation count $n$:
Centroid
$$\mathbf{p}^{(n+1)} = \frac{n \cdot \mathbf{p}^{(n)} + \mathbf{p}_{\text{new}}}{n + 1}$$CLIP Embedding
CLIP embeddings are re-normalized to the unit sphere after each update. This incrementally refines the semantic representation of each object without storing the full observation history.
5. Natural Language Query & Retrieval
Given a query string $q$, the system finds the best-matching object in the map.
The centroid $\mathbf{p}_{o^*}$ is projected to $z = 0$ and published as a Nav2 goal pose.
6. Remote GPU Inference
Remote inference was done with a combination of FastAPI and Uvicorn.
FastAPI was chosen for a key reason: Async I/O. Async def route handlers let the server handle image upload/decode without blocking while the GPU is busy, making it non-blocking for future multi-request scenarios.
Uvicorn was chosen because It’s the standard ASGI server for FastAPI. FastAPI is an ASGI framework and requires an ASGI-compatible server and Uvicorn fills that role.
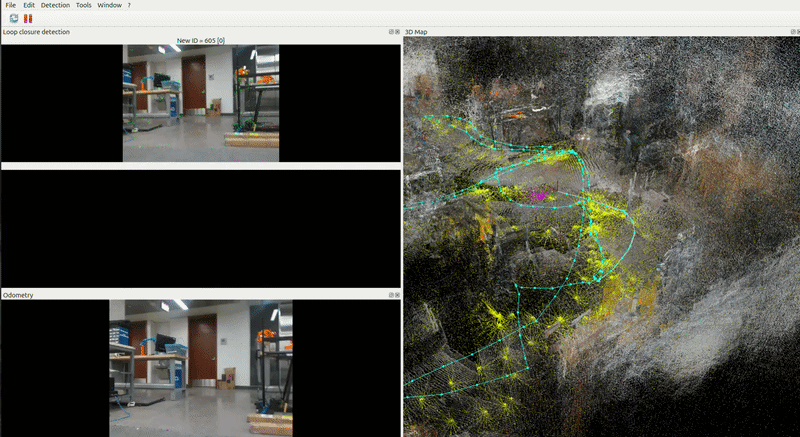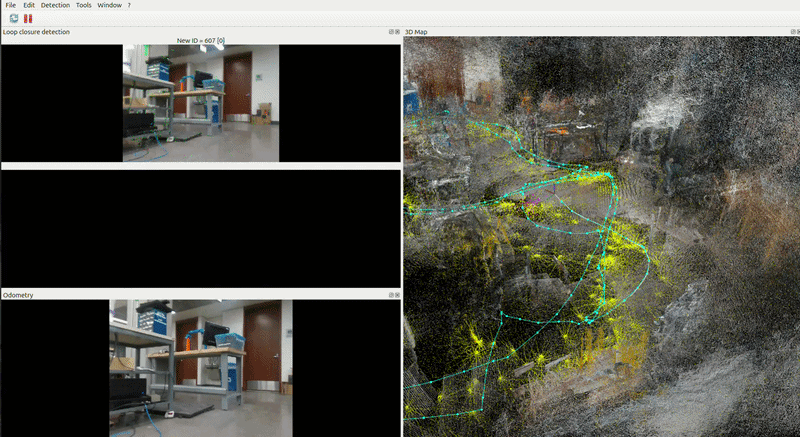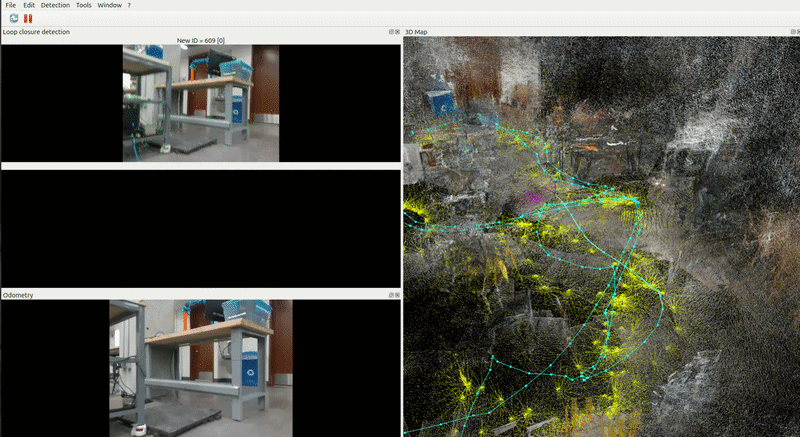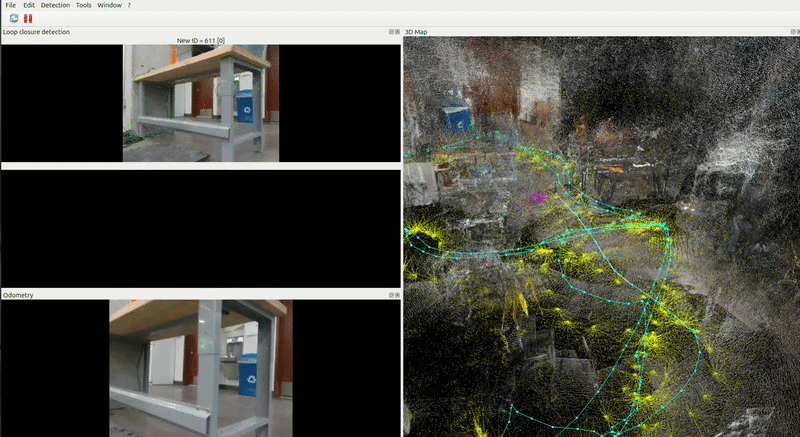
Nav 2 and RTAB-Map
Global Planner — SmacPlannerHybrid (Hybrid A*)
The global planner uses Hybrid A* which plans in the full $(x, y, \theta)$ configuration space rather than treating the robot as a point. This is appropriate for a legged robot where orientation matters for motion execution.
Local Controller — MPPIController
The local controller uses Model Predictive Path Integral (MPPI) control, a sampling-based MPC method that evaluates 1000 parallel trajectory rollouts and selects the optimal control via a weighted average.
RTAB-Map Integration with Nav2
RTAB-Map is the source of truth for the global reference frame. Its outputs feed Nav2 directly. RTAB-Map receives hardware odometry from the Go2 driver and publishing the corrected map → odom transform that Nav2 uses.
Reg/Strategy = 2 — visual features + ICP scan matching combined.
Frontier Exploration
Frontier exploration is an autonomous map-building strategy where a robot navigates to the boundaries between known free space and unknown space in order to systematically explore an environment. How It Works
- Frontier Detection — The occupancy grid (from SLAM) is scanned for cells
that border both free and unknown space. These edges are the frontiers. - Goal Selection — A frontier is selected as the next navigation target,
typically by some cost function (e.g., nearest frontier, largest unexplored
region, or information gain). - Navigation — The robot drives to the selected frontier using Nav2
- Map Update — As the robot moves, RTAB-SLAM updates the map, revealing new frontiers and marking old ones as explored.
- Repeat — The process continues until no frontiers remain (full coverage) or a stop condition is met.
While Frontier Exploration is still in progress, it should be implementable with minor modifications to the RTAB-Map Parameters.
Conclusions and Takeaways
PAWS demonstrates that a quadruped robot can build a persistent, language-queryable understanding of its environment in real time using off-the-shelf perception models and no task-specific training data. By coupling RTAB-Map’s keyframe-triggered mapping with a remotely hosted SAM3 + CLIP inference pipeline, the system grounds natural language queries to 3D map locations and autonomously navigates to them.
Future work.
The autonomous nearest frontier exploration algorithm is still in progress. With a full implementation, the Go2 should be able to autonomously build a map of it’s surroundings without guidance.
Another impactful next step would be integrating a captioning model (e.g. LLaVA or a smaller VQA model) alongside CLIP, so each map entry stores a short natural language description in addition to its embedding. This would unlock relational and affordance queries through an LLM reranking step rather than raw cosine similarity.